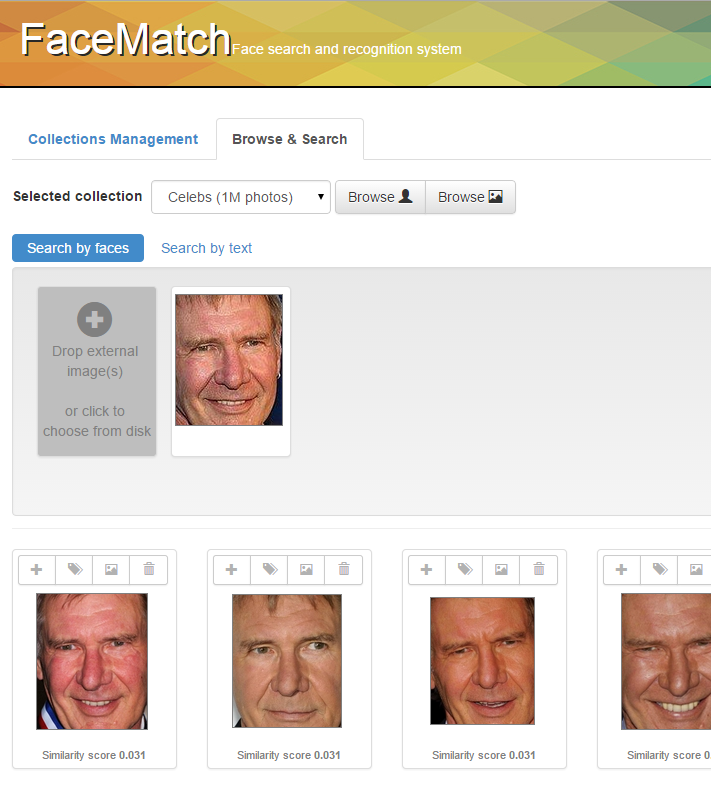
FaceMatch is a software technology for automatic detection and retrieval of human faces in static images. The main advantage of this technology is its ability to integrate multiple face detection and matching functions. The more state-of-the-art functions are provided, the more quality of face detection and retrieval should be. To be able to integrate novel functions into our technology, they have to provide API (application programming interface) support for (1) locating bounding boxes of faces within a static image for the detection phase and (2) extracting and measuring similarity of face features for the retrieval phase. The integration of provided functions is automatically tuned by the technology itself, so no additional requirements on the functions are necessary. The current version of the FaceMatch technology is demonstrated via a web application that effectively integrates the following three approaches for face retrieval as well as detection:
- FaceSDK (commercial software from ​Luxand),
- VeriLook SDK (commercial software from ​Neurotechnology),
- OpenCV (open-source software from ​Computer vision library) + MPEG-7 descriptors.
Another advantage of FaceMatch is its ability to efficiently search for the most similar faces even in large collections of static images/faces. This is achieved by indexing faces according to the MPEG-7 descriptor which is integrated in the technology all the time. Since the MPEG-7 descriptor satisfies metric postulates, we use the M-index structure to efficiently retrieve the candidate set of the 10,000 most similar faces. This candidate set is supposed to be sufficiently large to contain the desired number of the 100 most similar faces which are presented to a user. Such 100 faces are obtained by re-ranking the candidate set according to the aggregation function that integrates multiple face matching functions.
The whole technology works as follows. A user provides a collection of static images. The detection process is executed to localize all the human faces on the provided images. Then the extraction process is executed to extract specific characteristic features from each localized face. Since we always extract MPEG-7 features, we can build an index over such features that are extracted from all detected faces. This index is maintained by the M-index structure which is finally employed during the retrieval process to efficiently search for the candidate set of the most similar faces. More detailed information about the FaceMatch technology can be found here.
Related Publications
- J. Sedmidubsky, V. Mic, and P. Zezula: Face Image Retrieval Revisited. In 8th International Conference on Similarity Search and Applications (SISAP 2015). Springer-Verlag, 2015.
Open-source License
The FaceMatch technology is implemented in Java. The web application demonstrating functionality of this technology is implemented as a Java web application for Apache Tomcat. Both implementations are provided as open-source. In addition, we provide a virtual appliance in which the technology along with the web-application support is preinstalled — FaceMatch can be then simply accessed via a local web browser without necessity of any installation and configuration. The core of implementations can be downloaded here. For further information about the technology and web application as well as the virtual appliance can be acquired by contacting us at address: xsedmid [at] fi.muni.cz.
The FaceMatch technology is developed under the DISA Laboratory at the Faculty of Informatics, Masaryk University, Brno.
