Content
Introduction
FaceMatch is an application for a human face detection and recognition on a static images. It's main purpose is to demonstrate the abilities of an Aggregated search, with its higher quality results. FaceMatch application is divided into two parts: collections list and browse & search:- Collections list provides functions for the image collections maintanance:
- creating collections,
- deleting collections,
- renaming collections,
- adding images to collection.
- Browse & search page always relates to the given collection. It allows to:
- browse detected faces,
- browse uploaded images,
- browse the most similar faces found to the given face query.
Guidelines
- Collection list provides a list of independent image collections. The list of button functions follows:
- button renames collection – name is used just for user,
- button deletes collection – deletes collection and all images and faces in it,
- button starts browsing faces – shows all detected faces in a given collection,
- button starts browsing images – shows all loaded images in a given collection,
- button allows to add image(s) from your PC – load up to four images to the collection. Images are selected from a file system of a client's computer. Face detection is performed.
- button allows to add images from FTP folder – to extract big number of images, upload folder with images to our server and start extraction via this button. Faces are extracted from all images even in subdirectories, please upload only image files. File paths are not allowed to contain comma.
- Add new collection – creates a new independent image collection.
- Browse & search page enables to browse faces and images, and provides results of similarity search.
- Select collection to browse
Choose a collection to browse or search (if it wasn't chosen by clicking to appropriate button on Collections list page). -
Browsing faces or images selection
Two buttons for swapping between face and image browsing are next to selected collection name. - Face query box
Gray box is used to display selected faces, to which user wants to find the most similar faces. Searched is only selected collection.- There are two types of similarity function: MPEG-7 function and Aggregated function (see technology description).
- button assings a name to each face in a face query box. Name can be used for a search of named faces.
- button unselects all selected faces.
- Drop zone enables an „external queries“ – search the most similar faces to the face, which is not in a collection.
External image can be provided:- via url: drag an image from a web page and drop it into the drop zone. Please ensure you dragged an image source, not only another web page link.
- Or by a selection from a file system: click on the drop zone.
- Browsing faces
- Click on a face or button to add the face to the query faces.
- Click on the button to assign a name to the face.
- Click on the button to show (or hide) the entire image with this face. It's possible to add face to query faces, assing name to faces and delete faces from this image using buttons associated with each detected face on this image, as well as delete the whole image (with all detected faces in it).
- Click on the button to delete detected face. Even if all faces from an image are deleted, image is preserved in collection.
- Browsing images
- Click on an image or button to show the entire image with all detected faces (same function as in browsing faces).
- Click on the button to delete an image and all detected faces in it.
- Search results
-
As a result of similarity search, one hundred most similar faces are shown.
Aggregated similarity search combines the speed of MPEG-7 search using it's index, and the quality of Aggregated function.
In order to boost the search speed, a set of candidates is selected using an index, and these candidates are sorted with respect to Aggregated function.
This is made three times, using different sizes of candidate sets. These results are provided as
- Search results of aggregated function,
- Search results of enhanced aggregated function,
- Search results of double enhanced aggregated function,
- User may select corretly found faces and search visually similar faces to all selected faces in as a next iteration.
-
As a result of similarity search, one hundred most similar faces are shown.
Aggregated similarity search combines the speed of MPEG-7 search using it's index, and the quality of Aggregated function.
In order to boost the search speed, a set of candidates is selected using an index, and these candidates are sorted with respect to Aggregated function.
This is made three times, using different sizes of candidate sets. These results are provided as
- Search by text
- Write a name or it's part and search all faces with the name containing this text.
- User may select corretly found faces and search visually similar faces to all selected faces in as a next iteration.
Technology Description
FaceMatch is a technology for automatic detection and recognition of human faces on static images. The main advantage of this technology is its ability to aggregate multiple face recognition and detection functions. The more state-of-the-art functions are provided, the more quality of face detection and recognition should be. To be able to integrate novel approaches into our technology, they have to provide API (application programming interface) support for (1) locating bounding boxes of faces within a static image for the detection phase and (2) extracting and measuring similarity of face features for the recognition phase. The aggregation of provided functions is automatically tuned by the technology itself, so no additional requirements on functions are necessary. The current version of the FaceMatch technology is demonstrated via a web application that effectively combines the following 3 pieces of software for face recognition as well as detection:
- FaceSDK (commercial software from Luxand),
- VeriLook SDK (commercial software from Neurotechnology),
- MPEG-7 descriptors + OpenCV (open-source software from Computer vision library).
Another advantage of FaceMatch is its ability to efficiently search for the most similar faces even in large collections of static images/faces. This is achieved by indexing faces according to the MPEG-7 descriptor which is integrated in the technology all the time. Since the MPEG-7 descriptor satisfies metric postulates, we use the M-index structure to efficiently retrieve the candidate set of the 10,000 most similar faces. This candidate set is supposed to be sufficiently large to contain the desired number of the 100 most similar faces that are presented to a user. Such 100 faces are obtained by re-ranking the candidate set according to the aggregation approach that combines multiple face recognition functions.
The whole technology works as follows. A user provides a collection of static images. The detection process is executed to localize all the human faces on the provided images. Then the extraction process is executed to extract specific characteristic features from each localized face. Since we always extract MPEG-7 features, we can build an index over such features that are extracted from all detected faces. This index is maintained by the M-index structure which is finally employed during the recognition process to efficiently retrieve the candidate set of the most similar faces.
Face Detection
The output of the face detection process is a set of bounding boxes of faces which have been automatically localized within a static image. The FaceMatch technology combines multiple functions to maximize the detection precision. In particular, each provided function is used to independently detect the bounding boxes -- see Figure 1 where 3 functions of OpenCV, FaceSDK, and VeriLook SDK are utilized. Bounding boxes of individual approaches are grouped together in order to reveal the areas that overlapped. If most functions mark a given area as a face, there is a high probability that it is true positive. The current web application is set to require compliance of at least two detection functions (out of three) -- see Figure 2. Such setting aims at maximizing the precision, while keeping recall at a reasonably high value. On the contrary, if a high recall is required, the technology setting can be simply changed to unionize bounding boxes of detection approaches. Table 1 compares the values of precision and recall of independently used detectors along with our aggregation approach.

Figure 1: Bounding boxes of faces detected independently by OpenCV, FaceSDK, and VeriLook SDK (green, red, and blue colors).

Figure 2: Yellow bounding boxes illustrate the output of face detection by aggregating results of the three independent detectors.
| Name | Recall | Precision |
|---|---|---|
| OpenCV | 55 % | 89 % |
| FaceSDK | 63 % | 83 % |
| VeriLook SDK | 73 % | 84 % |
| Our aggregation approach | 62 % | 98 % |
Face Extraction & Indexing
The extraction process takes each detected face and tries to extract characteristic features that correspond to individual integrated functions. It can happen that some integrated function is not able to extract the specific feature even if the face has been properly detected, e.g., due to resolution limitations. However, this is not true for the MPEG-7 feature which can be extracted each time, disregarding the face quality. This results in an aggregated face feature that contains the MPEG-7 feature and possibly features of other integrated functions. In the current version of web application, each face is described by the composition of the MPEG-7 feature and eventually by features of FaceSDK and VeriLook SDK.
As soon as aggregated features are extracted from all the faces, they can be indexed. The indexing process utilizes only the metric-based MPEG-7 feature to build the M-index similarity-search structure. The more detailed information about M-index can found in the following publication.
Face Recognition
The face recognition process efficiently searches for 100 faces that are the most similar to a query face. Ideally, all the retrieved faces should correspond to the query person (in case they are available in the index). Moreover, the technology allows a user to specify multiple query faces (of the same person) at the same time with the objective to achieve the most precise result as possible. In the current version of technology, multi-query evaluation is simply based on executing single queries in parallel and merging their results with slight performance optimizations.
Searching for 100 the most similar faces is done by (1) efficient retrieval of candidate set of 10,000 faces that are similar to a query and (2) re-ranking of the candidate set by an aggregation function that should highlight 100 the most relevant faces. The second phase exploits knowledge of all integrated recognition functions and supposes that the candidate set retrieved on the basis of the MPEG-7 descriptor contains the most of relevant faces. We suppose that indexed datasets contain millions of faces. In case the dataset has less than 10,000 faces, it is not meaningful to utilize any index structure.
Aggregation Function
The retrieved candidate set is re-ranked (sorted) according to similarity of aggregated features, with respect to the aggregated query feature. Similarity between two aggregated face features is computed on the basis of partial similarities between integrated features of the same type. In the current version of web application, the aggregation similarity is measured on the basis of three partial similarities determined between MPEG-7, FaceSDK, and VeriLook SDK features. If a FaceSDK or VeriLook feature is not present at least at one of comparing faces, the corresponding partial similarity is set to infinity. The result aggregation similarity is determined as a minimum distance (dissimilarity) among computed partial similarities.
The partial similarity between two features of the same type is computed via a given integrated recognition function. The computed similarity is then normalized into [0, 1] so that partial similarities could be mutually compared. The normalization function is automatically estimated for each integrated recognition function during the initialization process of the technology. The normalization function is created on the basis of evaluation of precision of predefined queries that are executed on a sample of training data. Figure 3 depicts the results of precision and recall evaluated for individual integrated functions and the aggregation approach.
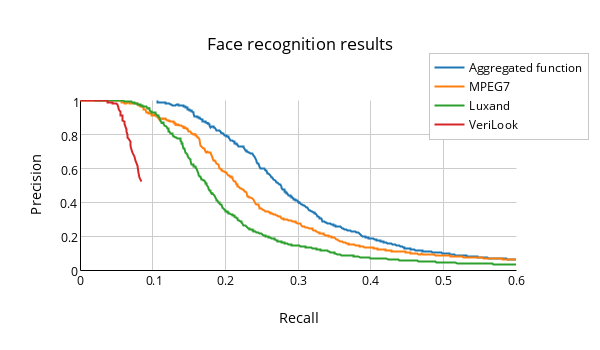
Figure 3: Comparison of results of recall and precision values evaluated for individual recognition functions against our aggregation approach.
Back to collection list page.